LLM Neuroanatomy III: Why RYS Works — The Language-Agnostic Middle
Probing a 27B model shows its middle layers organise by meaning, not by language or format — weak evidence against the strong Sapir-Whorf hypothesis, and the reason RYS works.

If you haven’t heard about the Sapir-Whorf hypothesis, don’t worry, I hadn’t either until I saw a comment on Twitter about my RYS part II article. Maciej Stachowiak dropped the comment regarding my small experiment comparing language vs topic in LLMs. The data suggested that the middle layers of Qwen3.5-27B were organised more by sentence topic than by language, with much less sensitivity to the language of the input.
Some weak evidence against at least the strong form of the Sapir-Whorf hypothesis. - @othermaciej
After digging into the topic, I found that the debate maps surprisingly well onto what we see inside transformer models. The Sapir-Whorf hypothesis is simply the idea that the language you think in shapes or determines what you can think, and has been debated in linguistics for nearly a century. It comes in two versions; both assume that cognition and language are deeply entangled:
Linguistic Determinism (Strong Version): The now-discredited view that language determines thought, limiting or restricting cognitive categories.
Linguistic Relativity (Weak Version): The widely accepted view that language structures influence speaker perception, shaping cognitive patterns without strictly limiting them.
Recent interpretability work (Wendler et al. 2024; Wu et al. 2024; Dumas et al. 2024) has established that transformer LMs build a shared, largely language-agnostic semantic space in their middle layers. What I do in this post is replicate that finding on five frontier-scale models, three of them MoEs, extend it to code and LaTeX with single-letter variables, and connect it to the part I think hasn’t been made explicit before: RYS layer duplication. The layers you can profitably duplicate without retraining are exactly the layers where the shared semantic space lives. The brain scan predicts the surgery map.
The same three-phase anatomy replicates cleanly across all five models.
Background: The Three-Phase Hypothesis
In LLM Neuroanatomy Part I, I showed that you can duplicate a block of middle layers in Qwen2-72B (with no weight changes, no training), and produce the #1 model on the HuggingFace Open LLM Leaderboard. The method, called RYS (Repeat Your Self), only works for layers in the middle of the transformer stack. Duplicating early or late layers breaks the model in weird ways.
That observation led to a hypothesis: transformer models have a three-phase functional anatomy.
- Decoding (early layers): convert surface-form tokens into an internal representation.
- Reasoning (middle layers): process meaning in a format-agnostic space.
- Encoding (late layers): convert the internal representation back into surface-form tokens.
In Part II, I confirmed that RYS generalises across models and model sizes, and I ran a small experiment (building on work by Evan Maunder) suggesting that the middle layers really do operate in a language-independent space. This post scales that experiment up, puts it in the context of the existing literature, and asks what the result means.
Related Work
The core empirical observation — that multilingual transformers develop a shared semantic representation in their middle layers — is not new. There is a well-cited body of prior work worth grounding this post in before I get to the parts I think are new. (Thanks to commenters on r/LocalLLaMA who pointed out the relevant references after Part II went up.)
Wendler, Veselovsky, Monea, and West (2024), “Do Llamas Work in English?”, is the foundational piece. Using the logit lens on Llama 2, they showed that intermediate hidden states for non-English prompts project closer to English unembeddings than to the input language’s own unembeddings. That observation seeded the subfield.
Wu, Yu, Yogatama, Lu, and Kim (2024), “The Semantic Hub Hypothesis” (ICLR 2025), is the closest prior art to what I do here. They extend the shared-representation claim across languages and modalities (arithmetic, code, vision, audio), add causal evidence via logit lens and activation steering, and draw an explicit analogy to the hub-and-spoke model from cognitive neuroscience (Patterson et al. 2007). If you read one paper on this topic, read theirs.
Dumas, Wendler, Veselovsky, Monea, and West (2024/25), “Separating Tongue from Thought”, runs activation-patching experiments on Llama 2 7B and shows that you can swap a concept while holding language fixed, and vice versa. Strikingly, mean-across-language concept vectors actually improve translation.
Fierro, Foroutan, Elliott, and Søgaard (2025), “How Do Multilingual Language Models Remember Facts?” (ACL Findings 2025), decomposes factual recall into a language-independent subject-enrichment stage and a language-specific object-extraction stage. That functional factorisation lines up cleanly with the encode/reason/decode picture from RYS Part I.
Sitting above all of these is the Platonic Representation Hypothesis (Huh, Cheung, Wang, and Isola, 2024), which argues that models trained on enough diverse data converge — across architectures and modalities — on a shared statistical representation of the underlying world. The language-agnostic middle is essentially a special case: if the Platonic claim holds, you’d expect multilingual transformers to converge on a language-invariant space for the same reason a vision model and a language model converge on similar object representations. Treat what follows as evidence consistent with that hypothesis on the multilingual axis.
So what does this post add on top?
- The RYS link. None of the above work connects the language-agnostic middle to a concrete intervention that measurably improves benchmarks. If the middle layers are the format-agnostic reasoning zone, those are exactly the layers where you can run the computation twice without breaking the model, and that is exactly where RYS layer duplication produces its gains. I think this is the real contribution here, and I’ll spend a whole section on it.
- Three-phase quantification at frontier scale. The encode and decode blocks look roughly constant at around 15 layers each; the reasoning block absorbs the remaining depth. This predicts, with no hand-waving, why RYS fails on small models: not enough stack to form a distinct middle region.
- Replication on recent, architecturally diverse systems, including 100B+ MoEs (Qwen3.5-27B, MiniMax M2.5, GLM-4.7, Gemma-4 31B, GPT-OSS-120B). The existing literature is mostly Llama-2/3 8B, GPT-2-XL, XGLM, and mT5.
- Code and LaTeX with single-letter variables. Wu et al. cover arithmetic and vision/audio; this adds programming and mathematical notation with effectively zero lexical overlap with the English prose.
- An interactive PCA widget so you can see the transition directly rather than taking my word for the cosine curves.
The Sapir-Whorf and Chomsky framing in the rest of the post is mine; I think it’s a useful angle on an otherwise well-studied phenomenon.
The Experiment
The setup is simple, and easy to replicate: Take eight languages spanning very different language families and writing systems:
- EN (English), FR (French) — Indo-European, Latin script
- ZH (Chinese), JA (Japanese), KO (Korean) — CJK
- AR (Arabic) — Semitic, right-to-left
- RU (Russian) — Cyrillic
- HI (Hindi) — Devanagari
And generate eight semantically distinct sentences on various topics: science, poetry, history, cooking, law, medicine, sports, economics.
Full Dataset (Click to expand)
- "EN_SCIENCE": "Photosynthesis converts light energy into chemical energy stored in glucose."
- "ZH_SCIENCE": "光合作用把光能转化为储存在葡萄糖中的化学能。"
- "AR_SCIENCE": "تحول عملية التمثيل الضوئي طاقة الضوء إلى طاقة كيميائية مخزنة في الجلوكوز."
- "RU_SCIENCE": "Фотосинтез преобразует световую энергию в химическую энергию, запасенную в глюкозе."
- "JA_SCIENCE": "光合成は光エネルギーをグルコースに蓄えられる化学エネルギーへ変換する。"
- "KO_SCIENCE": "광합성은 빛 에너지를 포도당에 저장되는 화학 에너지로 바꾼다."
- "HI_SCIENCE": "प्रकाश संश्लेषण प्रकाश ऊर्जा को ग्लूकोज़ में संचित रासायनिक ऊर्जा में बदलता है।"
- "FR_SCIENCE": "La photosynthese transforme l'energie lumineuse en energie chimique stockee dans le glucose."
- "EN_POEM": "At dusk, the moon lays silver on the tide while the wind carries a quiet song."
- "ZH_POEM": "黄昏时,月亮把银辉铺在潮汐上,风里带着一首安静的歌。"
- "AR_POEM": "عند الغسق يفرش القمر فضته على المد وتحمل الريح اغنية هادئة."
- "RU_POEM": "В сумерках луна расстилает серебро по приливу, а ветер несет тихую песню."
- "JA_POEM": "夕暮れに月は潮の上へ銀を敷き、風は静かな歌を運ぶ。"
- "KO_POEM": "해질 무렵 달빛이 밀물 위에 은빛을 깔고 바람은 조용한 노래를 실어 나른다."
- "HI_POEM": "सांझ में चांद ज्वार पर चांदी बिछा देता है और हवा एक शांत गीत लेकर चलती है।"
- "FR_POEM": "Au crepuscule, la lune pose de l'argent sur la maree tandis que le vent porte une chanson tranquille."
- "EN_HISTORY": "The printing press accelerated the spread of knowledge across Europe in the fifteenth century."
- "ZH_HISTORY": "印刷机在十五世纪加速了知识在欧洲的传播。"
- "AR_HISTORY": "سرعت المطبعة انتشار المعرفة عبر اوروبا في القرن الخامس عشر."
- "RU_HISTORY": "Печатный станок ускорил распространение знаний по Европе в пятнадцатом веке."
- "JA_HISTORY": "活版印刷は十五世紀のヨーロッパで知識の拡散を加速させた。"
- "KO_HISTORY": "인쇄기는 15세기 유럽 전역으로 지식이 퍼지는 속도를 높였다."
- "HI_HISTORY": "मुद्रण यंत्र ने पंद्रहवीं शताब्दी में पूरे यूरोप में ज्ञान के प्रसार को तेज कर दिया।"
- "FR_HISTORY": "L'imprimerie a accelere la diffusion du savoir en Europe au quinzieme siecle."
- "EN_COOKING": "To make soup, simmer onions, carrots, and beans until the broth becomes rich and fragrant."
- "ZH_COOKING": "做汤时,把洋葱、胡萝卜和豆子慢炖,直到汤汁变得浓郁而香。"
- "AR_COOKING": "لتحضير الحساء، اطه البصل والجزر والفاصوليا على نار هادئة حتى يصبح المرق غنيا وعطرا."
- "RU_COOKING": "Чтобы приготовить суп, томите лук, морковь и фасоль, пока бульон не станет насыщенным и ароматным."
- "JA_COOKING": "スープを作るには、玉ねぎ、にんじん、豆を煮込み、だしが濃く香るまで待つ。"
- "KO_COOKING": "수프를 만들려면 양파와 당근, 콩을 천천히 끓여 국물이 진하고 향긋해질 때까지 익힌다."
- "HI_COOKING": "सूप बनाने के लिए प्याज, गाजर और बीन्स को धीमी आंच पर पकाएं, जब तक शोरबा गाढ़ा और सुगंधित न हो जाए।"
- "FR_COOKING": "Pour preparer une soupe, faites mijoter des oignons, des carottes et des haricots jusqu'a ce que le bouillon devienne riche et parfume."
- "EN_LAW": "A contract becomes enforceable when both parties agree to clear terms and exchange consideration."
- "ZH_LAW": "当双方同意明确条款并交换对价时,合同就具有可执行性。"
- "AR_LAW": "يصبح العقد قابلا للتنفيذ عندما يوافق الطرفان على شروط واضحة ويتبادلان المقابل."
- "RU_LAW": "Договор становится подлежащим исполнению, когда обе стороны согласны с ясными условиями и обмениваются встречным предоставлением."
- "JA_LAW": "契約は、当事者双方が明確な条件に合意し、対価を交わしたときに執行可能になる。"
- "KO_LAW": "계약은 양측이 명확한 조건에 동의하고 대가를 교환할 때 집행 가능해진다."
- "HI_LAW": "जब दोनों पक्ष स्पष्ट शर्तों पर सहमत होते हैं और प्रतिफल का आदान-प्रदान करते हैं, तब अनुबंध लागू करने योग्य बनता है।"
- "FR_LAW": "Un contrat devient executoire lorsque les deux parties acceptent des conditions claires et echangent une contrepartie."
- "EN_MEDICAL": "Vaccination trains the immune system to recognize a pathogen before a real infection occurs."
- "ZH_MEDICAL": "疫苗接种会训练免疫系统在真正感染发生前识别病原体。"
- "AR_MEDICAL": "يدرب التطعيم الجهاز المناعي على التعرف على الممرض قبل حدوث عدوى حقيقية."
- "RU_MEDICAL": "Вакцинация обучает иммунную систему распознавать патоген до того, как произойдет настоящая инфекция."
- "JA_MEDICAL": "ワクチン接種は、実際の感染が起こる前に免疫系が病原体を見分けられるようにする。"
- "KO_MEDICAL": "백신 접종은 실제 감염이 일어나기 전에 면역 체계가 병원체를 알아보도록 훈련한다."
- "HI_MEDICAL": "टीकाकरण प्रतिरक्षा तंत्र को वास्तविक संक्रमण से पहले रोगजनक को पहचानना सिखाता है।"
- "FR_MEDICAL": "La vaccination entraine le systeme immunitaire a reconnaitre un agent pathogene avant qu'une veritable infection ne se produise."
- "EN_SPORTS": "A relay team wins when each runner exchanges the baton cleanly and maintains speed through every leg."
- "ZH_SPORTS": "接力队在每位跑者顺利交接接力棒并在每一棒保持速度时才能获胜。"
- "AR_SPORTS": "يفوز فريق التتابع عندما يسلم كل عداء العصا بسلاسة ويحافظ على السرعة في كل مرحلة."
- "RU_SPORTS": "Эстафетная команда побеждает, когда каждый бегун чисто передает палочку и сохраняет скорость на каждом этапе."
- "JA_SPORTS": "リレーチームは、各走者がバトンを確実に渡し、すべての区間で速度を保つと勝てる。"
- "KO_SPORTS": "계주 팀은 각 주자가 배턴을 깔끔하게 넘기고 모든 구간에서 속도를 유지할 때 승리한다."
- "HI_SPORTS": "रिले टीम तब जीतती है जब हर धावक बैटन को साफ़ी से सौंपता है और हर चरण में गति बनाए रखता है।"
- "FR_SPORTS": "Une equipe de relais gagne lorsque chaque coureur transmet le temoin proprement et conserve sa vitesse sur chaque portion."
- "EN_ECONOMY": "When interest rates rise, borrowing often slows and household spending can weaken."
- "ZH_ECONOMY": "当利率上升时,借贷往往会放缓,家庭支出也可能减弱。"
- "AR_ECONOMY": "عندما ترتفع اسعار الفائدة، يتباطا الاقتراض غالبا وقد يضعف انفاق الاسر."
- "RU_ECONOMY": "Когда процентные ставки растут, заимствования часто замедляются, а расходы домохозяйств могут ослабеть."
- "JA_ECONOMY": "金利が上がると、借り入れは鈍り、家計支出も弱くなりやすい。"
- "KO_ECONOMY": "금리가 오르면 차입이 둔화되고 가계 지출도 약해질 수 있다."
- "HI_ECONOMY": "जब ब्याज दरें बढ़ती हैं, तो उधार लेना अक्सर धीमा पड़ जाता है और घरेलू खर्च कमजोर हो सकता है।"
- "FR_ECONOMY": "Lorsque les taux d'interet augmentent, l'emprunt ralentit souvent et les depenses des menages peuvent faiblir."
That gives 64 sentences total (8 languages × 8 topics). The experiment is trivial: feed all 64 through an LLM model and extract the hidden-state representation at every layer. Then compute pairwise cosine similarity across all $C(64, 2) = 2016$ pairs.
This gives us three categories of comparison:
- Different-language, Same-content (224 pairs): e.g. English-science vs Chinese-science
- Same-language, Different-content (224 pairs): e.g. English-science vs English-cooking
- Different-language, Different-content (1568 pairs): e.g. English-science vs Arabic-poetry
To extract the hidden representation in PyTorch, this looks something like:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
def extract_hidden_states(model, inputs, *, pool: str = "mean_content"):
with torch.no_grad():
outputs = model(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
output_hidden_states=True,
use_cache=False,
)
if pool == "last_token":
states = torch.stack([h[0, -1, :].float() for h in outputs.hidden_states])
elif pool == "mean_content":
cs = inputs["content_start"]
ce = inputs["content_end"]
states = torch.stack([h[0, cs:ce, :].float().mean(dim=0) for h in outputs.hidden_states])
else: # mean_all
states = torch.stack([h[0, :, :].float().mean(dim=0) for h in outputs.hidden_states])
return states # shape: (num_layers + 1, hidden_dim)
We run a single forward pass per prompt, collect the hidden representation at every layer, and reduce each layer to one vector by averaging over the content tokens (mean_content, the default).
If language shapes thought (à la Sapir-Whorf), then the same-language pairs should be most similar in the reasoning layers, as thinking in the same language should produce more similar representations than thinking about the same topic in different languages. Put another way, we would expect these huge models to have a bunch of circuits that are focused on Chinese, and these are activated when reading and writing in Chinese while the French circuits lay dormant. That way, the model would be able to think in the idiosyncrasies of Chinese.
If language is just I/O, the opposite should happen: same-content pairs should dominate, regardless of language. That was kind of hinted at in RYS part II, but only between English and Chinese in a tiny experiment.
The Results
I ran this experiment on five models, from five different companies:
- Qwen3.5-27B (Alibaba, dense transformer, 64 layers)
- MiniMax M2.5 (MiniMax, 256-expert MoE, 62 layers)
- GLM-4.7 (Zhipu AI, 160-expert MoE, 92 layers)
- Gemma-4 31B (Google, dense transformer, 60 layers)
- GPT-OSS-120B (OpenAI, 128-expert MoE, 36 layers)
The three-phase anatomy replicates across all five.
Cosine Similarity Across Layers
Let’s take a look again at Qwen3.5-27B from Part 2, and see how expanding the experiment size affects the results. We would expect the middle layers to show the highest similarity for different-language, same-content pairs, once the model has transitioned into its reasoning space.
Centered cosine similarity for Qwen3.5-27B 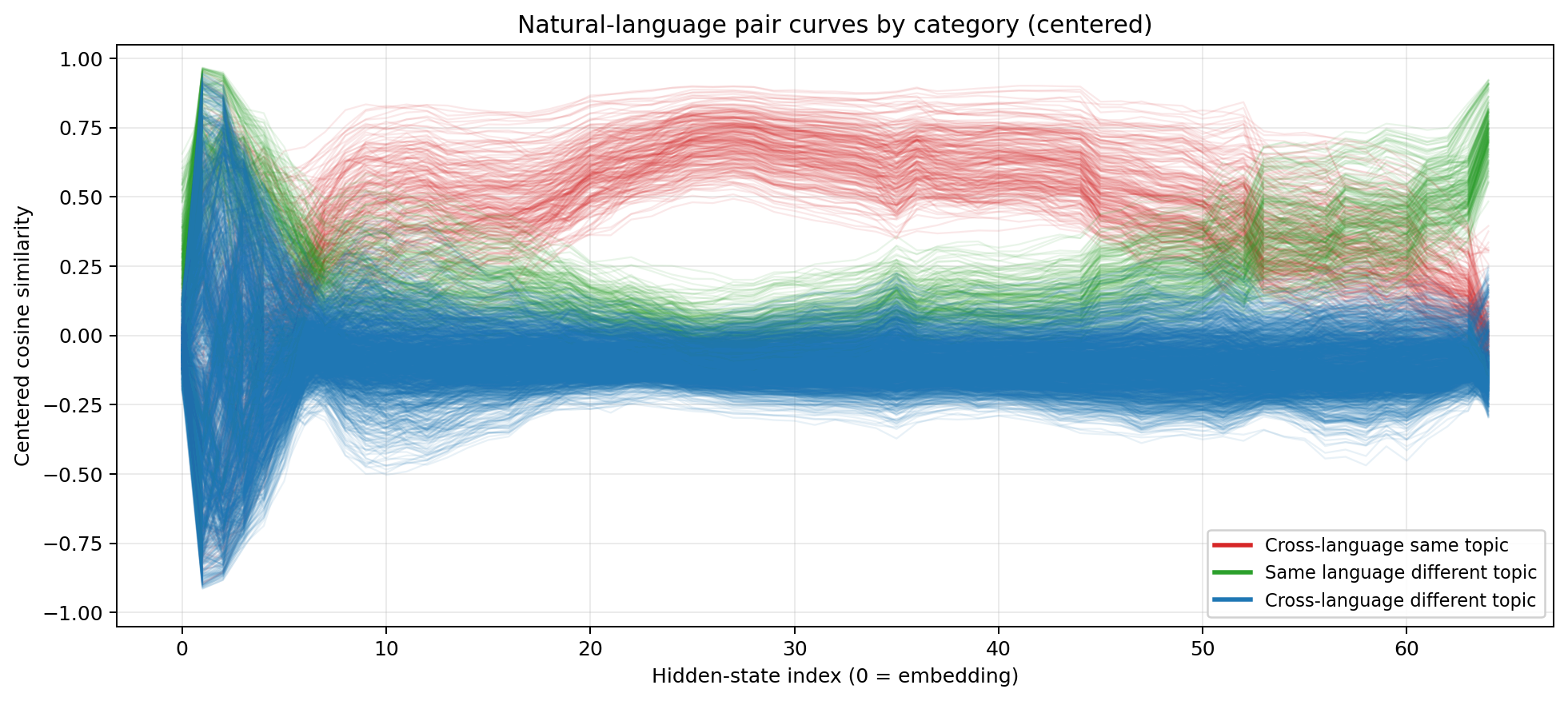 Red = different-language, same-content. Green = same-language, different-content. Blue = different-language, different-content. After per-layer centering, the organisation is stark.
Red = different-language, same-content. Green = same-language, different-content. Blue = different-language, different-content. After per-layer centering, the organisation is stark.
And this is exactly what we see: three phases emerge.
Decoding (layers 0–5). Wild oscillation, but green (same-language, different-content), has the highest similarity. The model knows what language it’s reading. English representations look like English. Chinese looks like Chinese. The model is doing heavy lifting to normalise radically different surface forms — different scripts, different tokenisations, different character sets.
Reasoning (layers ~10–45). Content dominates. The red line (different-language, same-content) sits above the green line (same-language, different-content). A sentence about photosynthesis in Hindi is more similar to a sentence about photosynthesis in Japanese than it is to a sentence about cooking in Hindi. Language identity has largely vanished; the average cosine similarity attributable to shared language is close to zero. The model has converged on a representation where meaning is the primary axis of organisation.
Encoding (layers ~45–64). Language specificity returns. The model is preparing to emit tokens, and it needs to commit to a specific language, script, and vocabulary. Cross-language similarity drops. The representations become surface-specific again, and by the final layer, the topic similarity has fallen to a cosine similarity of zero.
In the central layers, the model’s representations are organised more by meaning than by language. As we go on to examine the other models, we see the exact same pattern repeats across architectures:
Centered cosine similarity for MiniMax M2.5 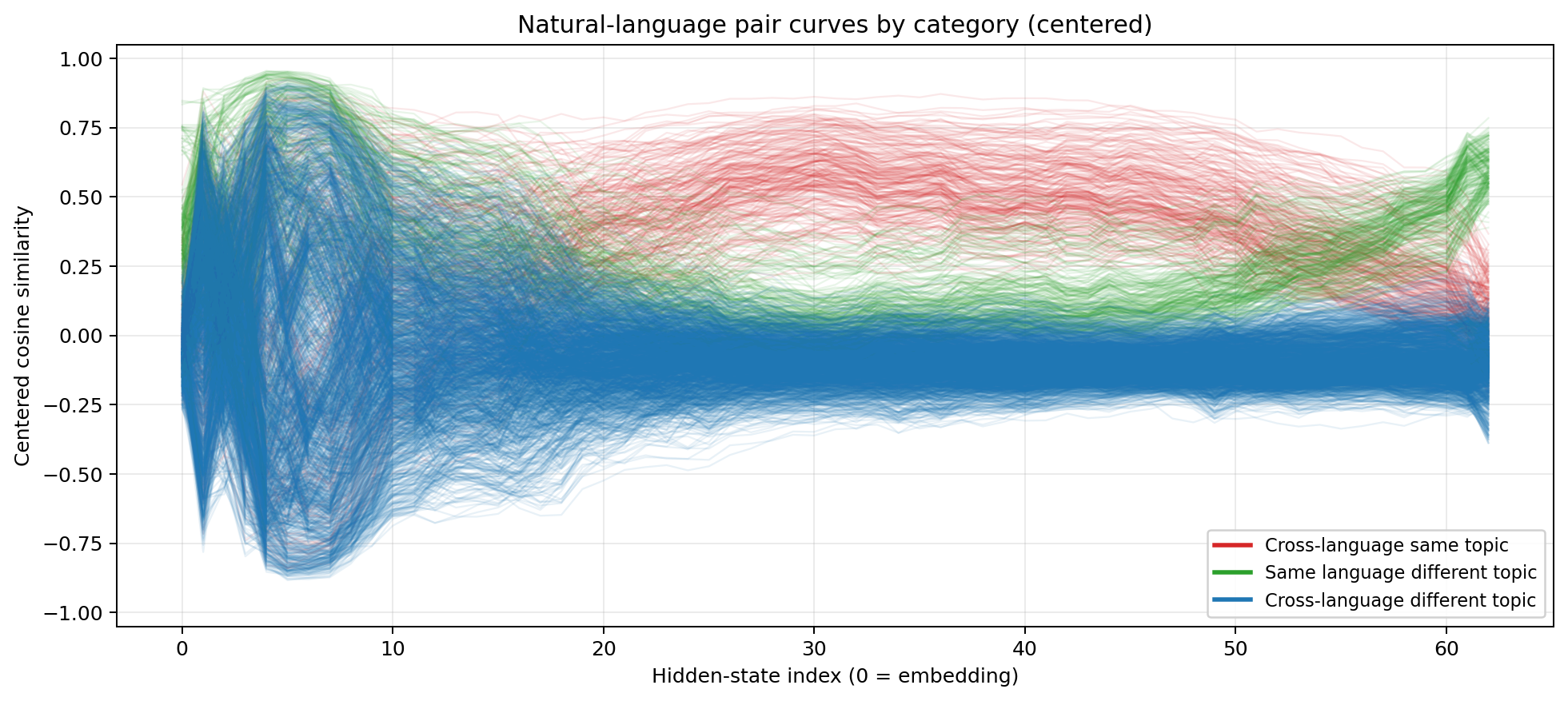 Red = different-language, same-content. Green = same-language, different-content. Blue = different-language, different-content.
Red = different-language, same-content. Green = same-language, different-content. Blue = different-language, different-content.
Centered cosine similarity for GLM-4.7 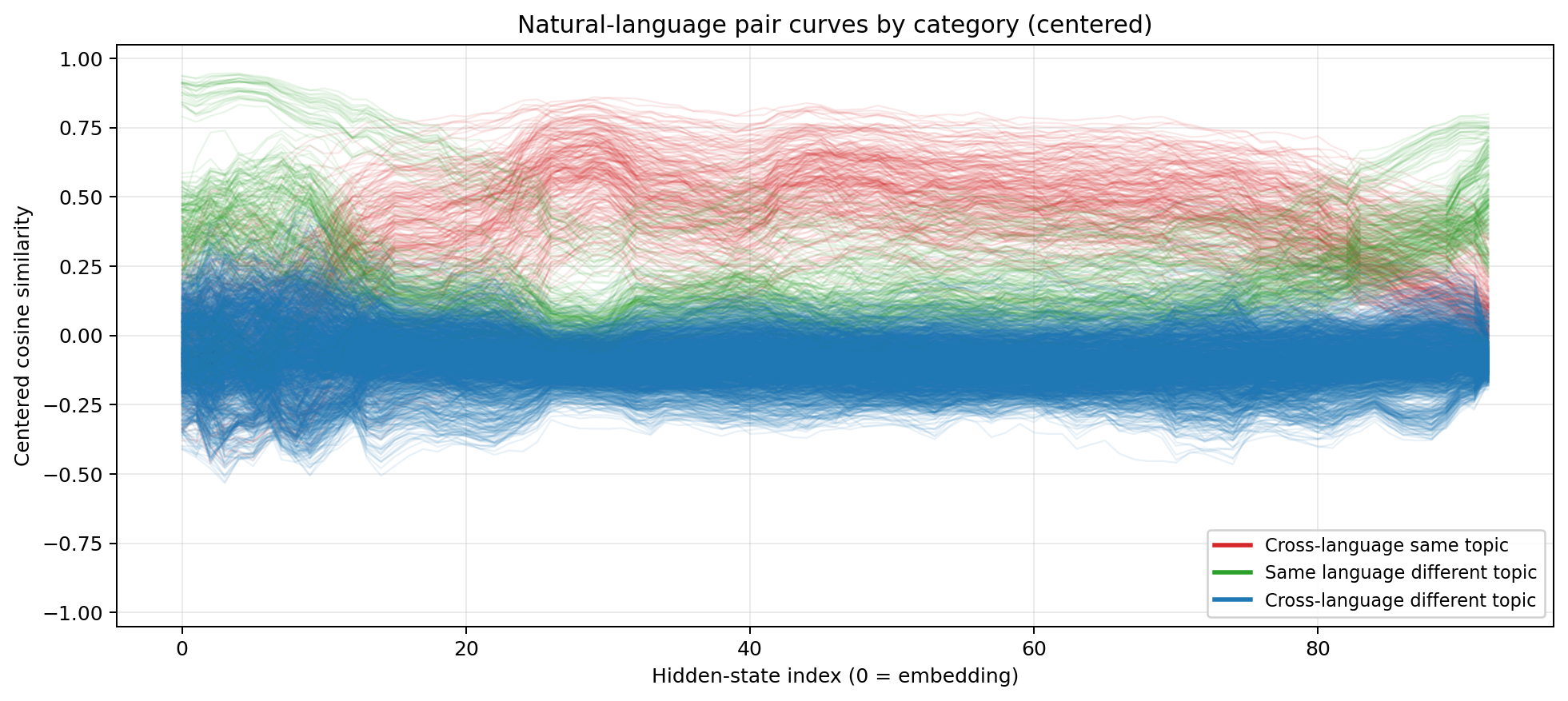 Same colour coding. The three-phase pattern replicates cleanly despite GLM-4.7’s 160-expert MoE architecture.
Same colour coding. The three-phase pattern replicates cleanly despite GLM-4.7’s 160-expert MoE architecture.
Centered cosine similarity for Gemma-4 31B 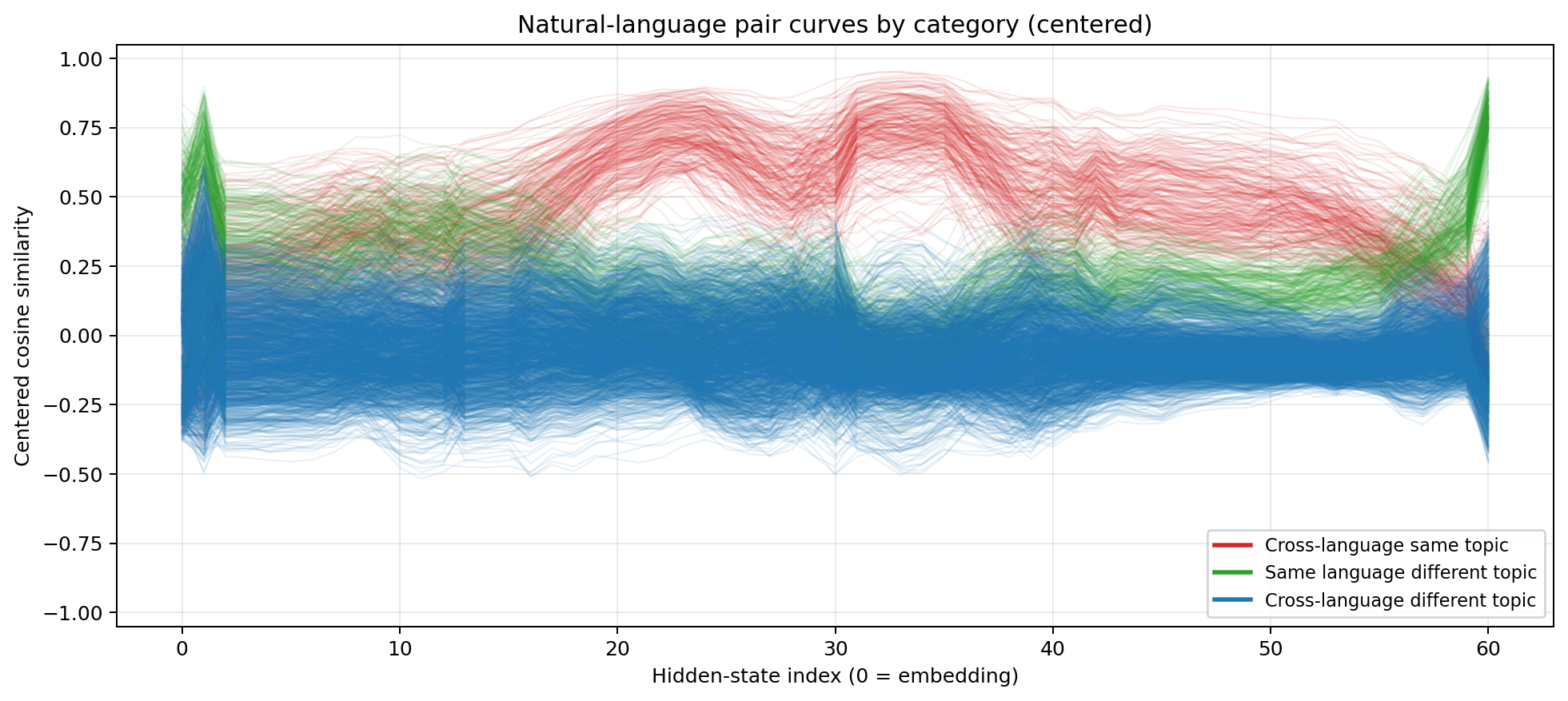 Same colour coding. With 60 layers, the small Gemma-4 31B compresses the same three phases but with interesting middle section forms.
Same colour coding. With 60 layers, the small Gemma-4 31B compresses the same three phases but with interesting middle section forms.
Centered cosine similarity for GPT-OSS-120B 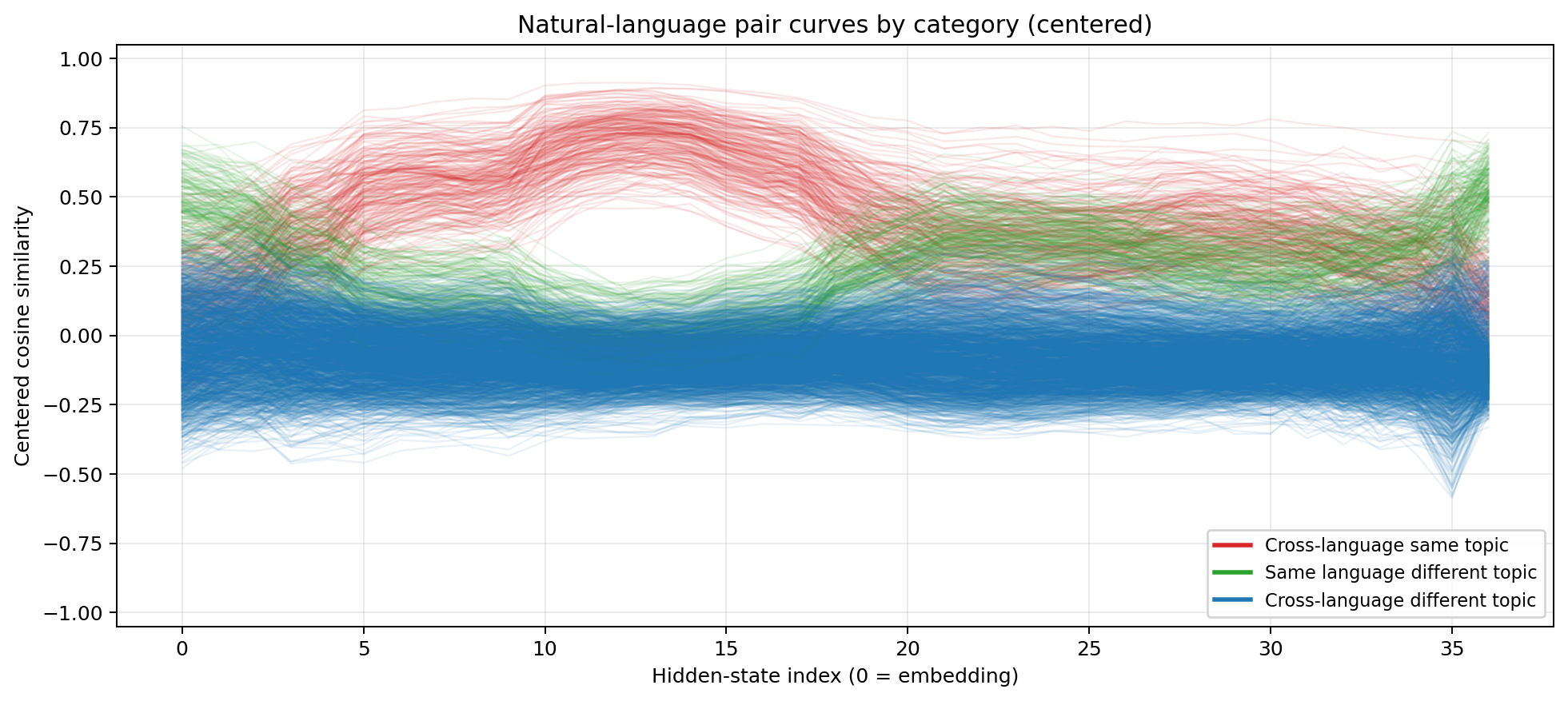 Same colour coding. Even with only 36 layers, GPT-OSS-120B compresses the same three phases into a shorter stack.
Same colour coding. Even with only 36 layers, GPT-OSS-120B compresses the same three phases into a shorter stack.
The interesting variable is the number of layers each model spends in the ‘reasoning’ zone. Empirically, the various models all seem to require about 15 layers to ‘encode’ reasoning back to text. This gives larger models with deeper transformer stacks like M2.5 and GLM-4.7 more time to stay in the zone during thinking. This coincides nicely with my original experiments from 2024: Small models don’t improve much with RYS. This is probably because the models just don’t have enough transformer layers to generate separate decoding, thinking and encoding layers. Duplicating layers in such a tight, optimised system breaks stuff! Once a model is big enough that pre-training allows for the formation of a distinct ‘thinking’ region, we can finally use the RYS method to find repeatable blocks that improve performance.
The PCA Visualisation
But the cosine similarity curves, while convincing, are still static graphs. To see the organisation directly, I ran Principal Component Analysis (PCA) on the hidden states at each layer, reducing each 7168-dimensional representation down to two dimensions so we can plot all 64 sentences in one scatter plot.
What PCA is doing. At each layer, every sentence is a point in a very high-dimensional space (one dimension per hidden unit). PCA finds the two directions in that space that capture the most variance — the two axes along which the 64 points spread out the most — and projects everything onto those axes. The result is a 2D scatter plot where distance encodes similarity: two points that are close together had similar internal representations at that layer, and two points far apart had dissimilar ones.
What clustering means. If all eight Chinese sentences land in one tight region, and all eight Arabic sentences land in another, and those two regions are far apart, it means the model is organising its representations primarily by language — the feature that most separates the 64 points is “which language is this?” Conversely, if all eight science sentences (across all languages) cluster together, and the cooking sentences form their own cluster, then the dominant organising principle is topic, not language. The geometry of the scatter plot is a direct read-out of what the model finds most salient.
A key advantage over the cosine similarity averages is that clusters are visible structurally, not just as a number. You can see whether the organisation is clean or messy, whether there are outliers, and crucially, whether the transition between language-organisation and topic-organisation is abrupt or gradual.
Try exploring the data yourself…
LayerScope
Aligned PCA of 64 sentence representations across layers. Points are coloured by language and shaped by topic. Early layers: language clusters. Middle layers: topic clusters. Late layers: language clusters return.
The interactive analysis makes the transition unusually vivid. In the early layers, the points cluster by language; in the middle, they reorganise by topic; and in the late layers, language structure reappears. In the early layers, the 64 points cluster into 8 tight groups, with one per language. Arabic with Arabic, Chinese with Chinese, regardless of what the sentences are about. By the middle of the stack, the clusters have completely reorganised: now there are 8 groups by topic! All the science sentences huddle together, regardless of whether they’re in Hindi or French. In the late layers, the language clusters re-emerge as the model prepares its output, and there is no longer any trace of the topic.
The model dissolves the concept of “language” in its middle layers and reconstructs it at the end.
Replication Across Architectures
Here’s the critical point: this isn’t a Qwen-specific artifact. MiniMax M2.5 is a 256-expert mixture-of-experts model, a fundamentally different architecture. GLM-4.7 is yet another design. GPT-OSS-120B shows the same broad anatomy as well. All five show the same three-phase structure, with the same dominance of content over language in the reasoning layers.
If five architecturally distinct models, trained by different organisations on different data mixes, all converge on the same internal organisation (language-agnostic reasoning flanked by language-specific encoding and decoding), then we’re not looking at a training artifact. We’re looking at a convergent solution. That’s consistent with what Wu et al. (2024) reported on smaller models; the contribution here is that the pattern holds up cleanly on 100B+ MoEs from five different labs.
Why RYS Works: The Anatomy Predicts the Surgery
This is the part I care about most, and the part I haven’t seen made explicitly anywhere else: the language-agnostic middle is the same middle where RYS layer duplication works.
The setup, in one sentence: take a block of middle layers in a big model, run it twice at inference (no retraining, no weight changes, just loop the forward pass), and you get measurable benchmark gains. Details and benchmarks are in Part I and Part II. Duplicating layers outside the middle breaks things in unpleasant ways. That asymmetry was the puzzle: why is the middle so privileged?
The cosine curves above give a mechanistic answer.
- In the middle region, the representation is format-agnostic. Each middle layer’s input and output live in the same kind of space: a shared semantic manifold where topic dominates and language identity has largely been stripped out. Feeding the output of a middle layer back into another middle layer is a soft in-distribution operation. The model can “think again” through the same circuit.
- Outside the middle, layers do format-specific work. Early layers are normalising eight scripts into one shared representation; late layers are committing back to a specific surface form. Looping a late layer back into itself means feeding it a decoded, language-specific representation when it was trained to consume a more abstract one. The distributions don’t match. The model snaps.
What makes this satisfying, rather than just a plausible story, is the size-scaling data. Across the five models in this post, the encoding and decoding blocks each look roughly constant at around 15 layers. The reasoning block absorbs whatever extra depth the architecture gives it. GPT-OSS-120B (36 layers) has only a handful of layers in a clean reasoning region; GLM-4.7 (92 layers) has a forty-layer plateau. This predicts, without hand-waving, why RYS works on big models and barely at all on small ones: small models don’t have enough stack to form a distinct format-agnostic middle, so anything you duplicate is partly doing encode/decode work and you’re feeding it the wrong distribution.
Read the other way: if you want to predict whether a new model will take well to RYS, you don’t need the full benchmark sweep. Run the 64-sentence cosine scan first. Clean three-phase structure with a sizeable middle plateau → there is room to cut. Smeared three phases → don’t bother.
The brain scan predicts the surgery map.
What This Means for Sapir-Whorf
The Sapir-Whorf hypothesis exists in two forms.
The strong version (linguistic determinism) says the language you speak determines what thoughts you can have. This is already unfashionable in linguistics, and from what I read, most linguists favour the weak version. But it’s never been empirically refuted in a controlled system where you can actually poke around the internal representations.
LLMs are that controlled system, and note that I’m not claiming humans operate at all in the same way. The empirical observation (again, not original to me; see the Related Work section) is that the model’s internal representations, in the layers where reasoning happens, are not organised by language. The cosine similarity between different samples in the same language drops to approximately zero in the middle layers. In these layers, language identity is no longer the main geometric organiser of the representation; semantic content is.
Now, careful reader, you have probably already guessed what this experiment does and doesn’t show. It shows that the model categorises meaning universally, the same topic maps to the same region of the internal space regardless of language. It doesn’t directly show that the model reasons identically in all languages. Sapir-Whorf, in its most interesting form, isn’t about whether you can express the same ideas in different languages (everyone agrees you can). It’s about whether the structural quirks of a language, like mandatory tense marking, grammatical gender, and evidentiality systems, are all subtly shaping how you process information.
That subtler question remains open. But what the data does show is that LLMs create what you might call an anti-Whorfian bottleneck: a structural separation of language from reasoning. Whatever language-specific biases enter through the decoding layers, the mid-stack appears to strip much of them out on the way to a shared semantic representation. The model is architecturally incentivised (by gradient descent, not by design) to undo Whorfian relativity in its reasoning layers.
The weak version (linguistic relativity) says language influences thought. This is subtler and probably still holds. The encoding layers do carry language-specific structure into the stack. Different tokenisations affect how information enters the model. Languages with rich morphology pack more information per token than analytic languages. These differences likely influence downstream processing, even if the mid-stack representation is approximately universal.
But here’s the key distinction: influence is not determination. The model converges on a shared reasoning space despite radically different surface forms. Arabic (right-to-left, consonantal root system), Japanese (mixed script, agglutinative), and English (SVO, relatively simple morphology) all arrive at the same internal representation of “photosynthesis converts light energy into chemical energy.”
The model appears to learn an interlingua: a high-dimensional geometric structure that represents meaning more directly than surface form. A future article in this series will probe the geometry in more detail.
The Chomsky Connection (Or: Everyone Was Half Right)
There’s a deeper irony here, and his name is Noam Chomsky.
Chomsky’s Universal Grammar hypothesis, proposed in the 1950s and refined over decades, holds that all human languages share an innate deep structure. Surface forms vary wildly (SVO vs SOV word order, inflectional vs analytic morphology, tonal vs non-tonal phonology), but underneath, there’s a universal computational skeleton that all languages map onto. Chomsky argued this structure is biologically innate, and hardwired into the human language faculty, part of our genetic endowment. Crucially, Chomsky’s deep structure is syntactic: it’s about the rules that govern how words combine, how phrases nest, how recursion works.
What the transformers found is something different. The universal representation in the mid-stack isn’t organised by syntax, it’s organised by semantics. The PCA plots don’t show sentences clustering by grammatical structure (SVO languages together, SOV languages together). They show sentences clustering by meaning (all the photosynthesis sentences together, regardless of grammar).
Look at the three-phase anatomy again:
- Decoding layers take radically different surface forms (different scripts, different word orders, different morphological strategies) and map them onto a shared internal representation.
- Reasoning layers operate in that shared space, indifferent to which surface form or syntactic structure produced it.
- Encoding layers map back out to a specific surface form.
This flow occurs over and over, for each processed token.
The encoding and decoding phases are doing something analogous to what Chomsky’s framework describes: translating between diverse surface structures and a universal deep structure. Syntactic structure must still be handled somewhere — presumably in the initial decoding layers — but the deep structure the model actually converges on isn’t a tree of syntactic rules. What lives in the middle layers is different: a continuous geometric manifold of meaning. Every language gets its own encoder and decoder, but the middle is shared, and what’s shared is semantics, not syntax.
Chomsky famously demonstrated that syntax and semantics are independent systems with the phrase “Colorless green ideas sleep furiously”, which is grammatically impeccable and semantically absurd. His argument was that syntax must therefore be the foundational, primitive system: an innate rulebook that operates prior to and independently of meaning. What the transformers show is the opposite priority. It seems that gradient descent can build universal linguistic structure entirely out of semantics, with no foundational syntactic rulebook at all. Syntax, in this picture, is downstream: a surface regularisation that emerges from the need to serialise meaning into a linear token stream, not the bedrock on which meaning rests.
Chomsky was right about the what: there is a universal structure underlying all languages. For LLMs, it’s all about the where (it’s semantics, not syntax) and the how (it’s learned geometry, not innate grammar). The universal structure isn’t a set of rules, parameters, or syntactic primitives. It’s a high-dimensional space where semantic relationships are encoded as distances and directions. It emerges from exposure to enough linguistic diversity through gradient descent. The optimisation pressure of next-token prediction on multilingual data was sufficient: the model learns that the most efficient way to be smart in 100 languages is to strip language away entirely in the middle.
So we end up with a three-way scorecard:
Chomsky: “There’s a universal deep structure underlying all languages.” → Right intuition, wrong floor — at least for LLMs. He looked for it in syntax. In LLMs, it lives in semantics. And in LLMs, it isn’t innate; it’s emergent from gradient descent on multilingual data. Whether any of this generalises to human cognition is a separate question, and one I’m not qualified to answer.
Sapir-Whorf: “Language shapes (or determines) thought.” → In these models, the strong form does not fare well. These models structurally separate language from reasoning — an anti-Whorfian bottleneck baked into the architecture by gradient descent. Language is the I/O layer, not the reasoning layer.
The transformers: “We’ll just learn whatever works.” → Converge on a universal semantic space that vindicates Chomsky’s intuition about universality while contradicting his mechanism entirely.
Caveats and What This Isn’t
The shared semantic space itself is not a new finding. Wu et al. (2024), Dumas et al. (2024), Wendler et al. (2024), and others established it on smaller models. What I add here is the link to RYS, the three-phase quantification on frontier-scale models, and the extension to code and LaTeX.
“Isn’t this just a predictable consequence of information-bottleneck theory?” A fair point raised by several commenters, and yes, mostly. Any architecture that has to pass many input distributions through a shared parameter budget is under pressure to compress towards a common latent space; classical encoder-decoders were designed to exhibit exactly this behaviour, and decoder-only transformers inherit the same pressure implicitly. So the existence of a shared mid-stack space is not a surprise to anyone who has thought about bottlenecks. What the Wu / Dumas / Wendler line of work contributed empirically was showing it cleanly in modern LLMs; what I contribute on top is the link between the compressed region and RYS, plus the layer-count scaling. The qualitative phenomenon was predictable; the quantitative geometry of where the bottleneck sits in a 92-layer stack wasn’t, and that is the part that matters for layer duplication.
LLMs aren’t human brains. Sapir-Whorf is a hypothesis about human cognition, thought up nearly a century before LLMs. I’m not claiming that because GPT-scale transformers have language-independent reasoning, therefore human cognition is language-independent. That would be dumb, right?
But LLMs are an unprecedented empirical tool for this question. They are the first systems we can build that process many natural languages at high competence, develop internal representations we can measure at every layer, and let us directly test whether thought is language-shaped or language-independent. Before LLMs, you could only study Sapir-Whorf by comparing human behaviour across language groups, which is messy, confounded, and hard to control. Now we can read out the internal state and ask: is it organised by language or by meaning?
To the cognitive scientists currently screaming at their screens: yes, I know LLMs are disembodied text-engines with no sensorimotor grounding. Yes, I know “photosynthesis” is an easy 1:1 translation compared to testing culturally entangled concepts like Schadenfreude or Quechua evidentiality. Yes, I know modern linguists favour the weak Whorfian view anyway. And yes, 64 sentences is a proof of concept, not a definitive corpus study. But the architectural observation remains: we have a computational substrate that processes 100+ languages, and it builds an anti-Whorfian bottleneck. That’s interesting, right?
On parallel corpora and the translation-artifact objection. A careful reader will note that training data contains parallel corpora (there are lots of human-translated sentence pairs), and argue that gradient descent simply had to learn a shared latent space because that is the mathematically optimal way to predict translations. This is a pretty fair mechanistic objection, but it doesn’t discredit the result. The question of why the model learns a shared space doesn’t negate the fact that it does! The question “is this universal meaning, or just a reverse-engineering of the human semantic map?” may not have a clean answer, because human language and human meaning are co-constituted.
Is the “universal” space just latent English? Finally, a legitimate concern. But the strongest counter is architectural: Qwen and GLM are both Chinese-dominant models, trained by Chinese organisations on Chinese-heavy data. If the universal space were latent English, you’d expect Chinese-dominant models to produce a different organising structure — one centred on Chinese rather than English. They don’t. All five models, including the Chinese-heavy ones, converge on the same three-phase anatomy with the same topic-dominant reasoning layers. A shared structure that is independent of each model’s dominant training language is hard to explain as “latent English.” A rigorous distance-from-centroid analysis is still on the list to confirm this quantitatively.
Beyond Language: Code and Math as a Test Case
The natural-language results are clean, but they invite an obvious question: is the universal space specific to human languages, or does it extend to formal systems too?
Natural languages, for all their diversity, share a common evolutionary purpose: humans communicating with other humans about a shared physical world. You could argue that convergence across Chinese and French is unsurprising, as they’re all trying to do the same thing. Code and mathematical notation are a different beast entirely. They weren’t shaped by evolution or culture. They express computation and formal relationships using systems that share essentially zero surface structure with any natural language.
If the model processes Python code, LaTeX equations, and English descriptions of the same concept, do they converge in the mid-stack the way Chinese and French do?
Natural languages all describe the world using nouns, verbs, and compositional semantics. Python expresses computation using operators and control flow. LaTeX expresses mathematical relationships using a completely different notation system — $\frac{1}{2} m v^2$ shares essentially zero surface tokens with either $0.5 * m * v ** 2$ or “half the mass times velocity squared.” Three fundamentally different modalities, zero syntactic overlap.
To make it honest, the code uses only single-letter variables. No velocity, no principal, no kinetic_energy. Just m, v, p, r, t — standard math convention, not English words. The model has to understand the computation, not read the labels. I tested 12 topics spanning physics, mathematics, and economics — from kinetic energy and gravitational force to the quadratic formula and price elasticity of demand. Each topic expressed in all three systems gives 36 samples, 630 pairwise comparisons. A few representative triplets:
Kinetic energy:
- EN: “The kinetic energy of a moving object equals one half of its mass multiplied by the square of its velocity.”
- Python:
1 2
def f(m, v): return 0.5 * m * v ** 2
- LaTeX: $\ E_k = \frac{1}{2} m v^2$
Quadratic formula:
- EN: “The solutions of a quadratic equation are found by taking the negative of the second coefficient, plus or minus the square root of that coefficient squared minus four times the first and third coefficients, all divided by twice the first coefficient.”
- Python:
1 2 3
def f(a, b, c): d = (b**2 - 4*a*c)**0.5 return (-b + d)/(2*a), (-b - d)/(2*a)
- LaTeX: $\ x = \frac{-b \pm \sqrt{b^2 - 4ac}}{2a}$
Present value:
- EN: “The present value of a future cash flow is that amount divided by one plus the discount rate raised to the number of periods.”
- Python:
1 2
def f(fv, r, t): return fv / (1 + r) ** t
- LaTeX: $\ PV = \frac{FV}{(1 + r)^t}$
Full Dataset: Code and Math (Click to expand)
- "EN_KINETIC_ENERGY": "The kinetic energy of a moving object equals one half of its mass multiplied by the square of its velocity."
- "PY_KINETIC_ENERGY": "def f(m, v):\n return 0.5 * m * v ** 2"
- "LATEX_KINETIC_ENERGY": "E_k = \frac{1}{2} m v^2"
- "EN_GRAVITATIONAL_FORCE": "The gravitational force between two objects is proportional to the product of their masses and inversely proportional to the square of the distance between them."
- "PY_GRAVITATIONAL_FORCE": "def f(m1, m2, r, G=6.674e-11):\n return G * m1 * m2 / r ** 2"
- "LATEX_GRAVITATIONAL_FORCE": "F = G \frac{m_1 m_2}{r^2}"
- "EN_OHMS_LAW": "The electric current through a conductor is equal to the voltage across it divided by its resistance."
- "PY_OHMS_LAW": "def f(V, R):\n return V / R"
- "LATEX_OHMS_LAW": "I = \frac{V}{R}"
- "EN_PERIOD_OF_A_PENDULUM": "The period of a simple pendulum is two pi times the square root of its length divided by gravitational acceleration."
- "PY_PERIOD_OF_A_PENDULUM": "def f(L, g=9.81):\n return 2 * 3.14159 * (L / g) ** 0.5"
- "LATEX_PERIOD_OF_A_PENDULUM": "T = 2\pi \sqrt{\frac{L}{g}}"
- "EN_FACTORIAL": "The factorial of a positive integer is the product of all positive integers less than or equal to that number."
- "PY_FACTORIAL": "def f(n):\n r = 1\n for i in range(1, n + 1):\n r *= i\n return r"
- "LATEX_FACTORIAL": "n! = \prod_{i=1}^{n} i"
- "EN_QUADRATIC_FORMULA": "The solutions of a quadratic equation are found by taking the negative of the second coefficient, plus or minus the square root of that coefficient squared minus four times the first and third coefficients, all divided by twice the first coefficient."
- "PY_QUADRATIC_FORMULA": "def f(a, b, c):\n d = (b**2 - 4*a*c)**0.5\n return (-b + d) / (2*a), (-b - d) / (2*a)"
- "LATEX_QUADRATIC_FORMULA": "x = \frac{-b \pm \sqrt{b^2 - 4ac}}{2a}"
- "EN_EULERS_IDENTITY": "Euler's identity states that the exponential of the imaginary unit times pi, plus one, equals zero."
- "PY_EULERS_IDENTITY": "import cmath\nassert abs(cmath.exp(1j * cmath.pi) + 1) < 1e-10"
- "LATEX_EULERS_IDENTITY": "e^{i\pi} + 1 = 0"
- "EN_AREA_OF_A_CIRCLE": "The area enclosed by a circle is equal to pi multiplied by the square of its radius."
- "PY_AREA_OF_A_CIRCLE": "def f(r):\n return 3.14159 * r ** 2"
- "LATEX_AREA_OF_A_CIRCLE": "A = \pi r^2"
- "EN_COMPOUND_INTEREST": "Compound interest grows an initial principal by applying a fixed annual rate repeatedly over a number of years, so that each year's interest earns interest in subsequent years."
- "PY_COMPOUND_INTEREST": "def f(p, r, t):\n return p * (1 + r) ** t"
- "LATEX_COMPOUND_INTEREST": "A = P(1 + r)^t"
- "EN_PRICE_ELASTICITY_OF_DEMAND": "Price elasticity of demand is the ratio of the percentage change in quantity demanded to the percentage change in price."
- "PY_PRICE_ELASTICITY_OF_DEMAND": "def f(dq, q, dp, p):\n return (dq / q) / (dp / p)"
- "LATEX_PRICE_ELASTICITY_OF_DEMAND": "E_d = \frac{\Delta Q / Q}{\Delta P / P}"
- "EN_GDP_DEFLATOR": "The GDP deflator is nominal gross domestic product divided by real gross domestic product, multiplied by one hundred."
- "PY_GDP_DEFLATOR": "def f(n, r):\n return (n / r) * 100"
- "LATEX_GDP_DEFLATOR": "D = \frac{GDP_{nominal}}{GDP_{real}} \times 100"
- "EN_PRESENT_VALUE": "The present value of a future cash flow is that amount divided by one plus the discount rate raised to the number of periods."
- "PY_PRESENT_VALUE": "def f(fv, r, t):\n return fv / (1 + r) ** t"
- "LATEX_PRESENT_VALUE": "PV = \frac{FV}{(1 + r)^t}"
Centered cosine similarity for MiniMax M2.5 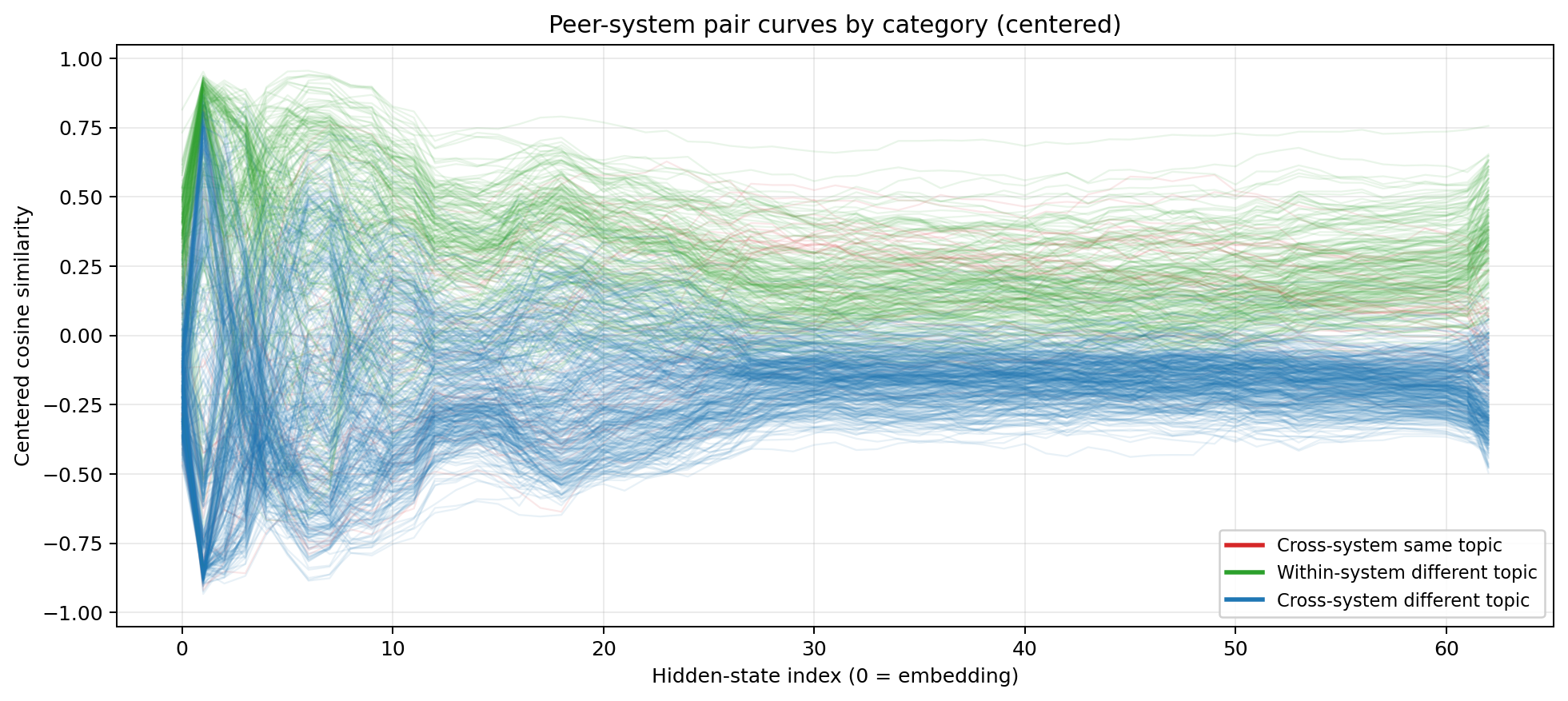 Centered cosine similarity across English, Python, and LaTeX. Red = different system same-topic. Green = within-system different-topic. Blue = different system different-topic.
Centered cosine similarity across English, Python, and LaTeX. Red = different system same-topic. Green = within-system different-topic. Blue = different system different-topic.
Centered cosine similarity for MiniMax M2.5 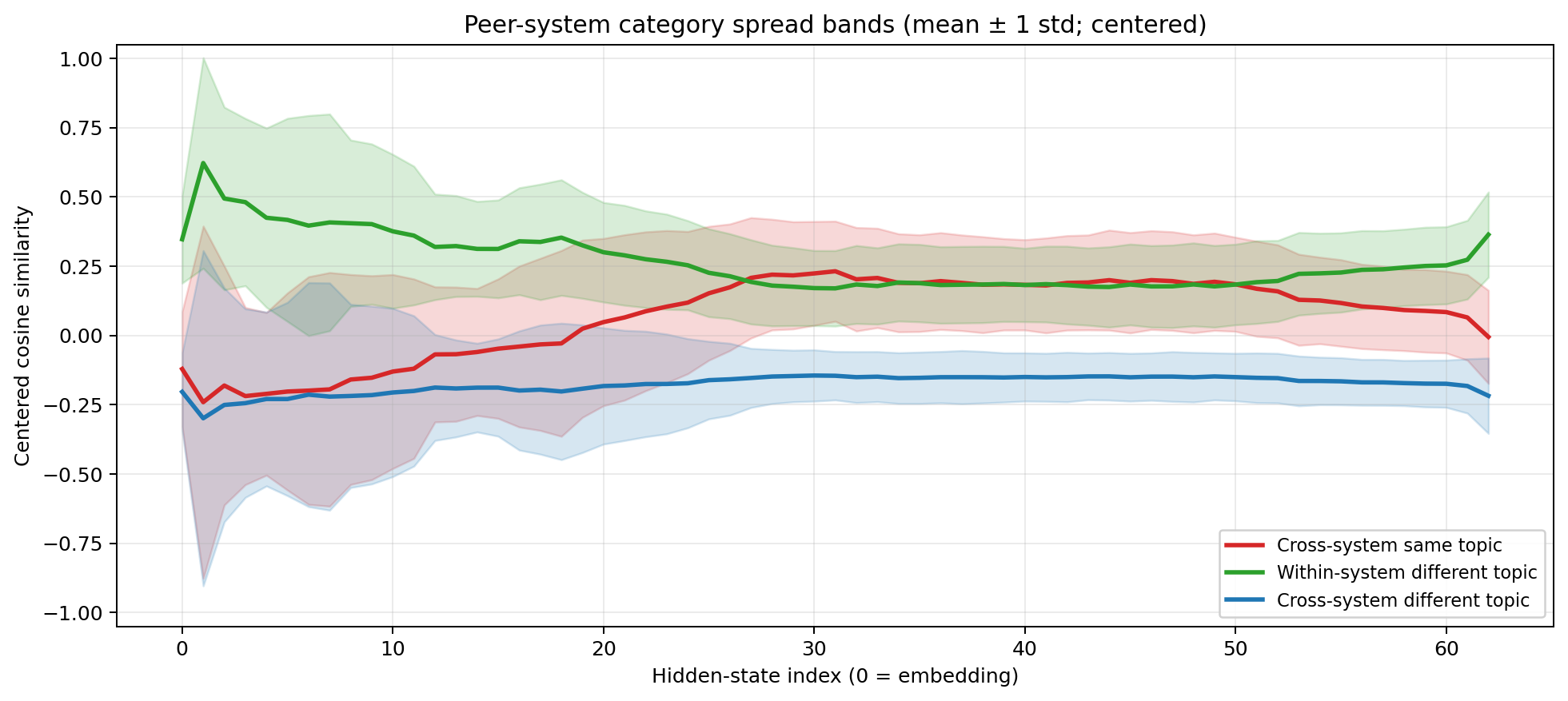 Same data with ±1 standard deviation bands.
Same data with ±1 standard deviation bands.
The results are not as clear now. There are still three phases, same as the natural language case, but now across modalities. However, the middle layers show a blend between format and semantics, as opposed to pure semantics as with language comparisons:
Layers 0–30: System identity dominates. The green line (same-system, different-topic) peaks above 0.6, and then steadily falls to ~0.2. The red line (different-system, same-topic) starts at below -0.2 and rises to ~0.25, slightly higher than the green line. Early in this phase, the model overwhelmingly sees “this is Python” versus “this is LaTeX” versus “this is English.” The distinction between executable code, mathematical notation, and natural language prose swamps everything else.
Layers 30–52: Topic has caught up. Red sits slightly above green, so $\ \frac{1}{2} m v^2$ is now slightly closer to “kinetic energy equals half mass times velocity squared” than it is to $\ A = \pi r^2$. A Python function computing compound interest clusters with the English description of compound interest and the LaTeX formula for compound interest, and not with a Python function computing something else. And blue (different-system, different-topic) stays firmly negative throughout, confirming that the model isn’t just blurring everything together. It’s maintaining semantic discrimination while erasing format discrimination.
Layers 52+: System identity returns. Green spikes back up, and red falls. The model is preparing to emit tokens and needs to commit: Python syntax, LaTeX markup, or English words.
The universal space in the mid-stack isn’t just language-agnostic — it’s becoming modality-agnostic. It encodes meaning whether that meaning arrives as French prose, Arabic script, Python functions with single-letter variables, or LaTeX notation. $\ \frac{1}{2} m v^2$ and “half the mass times velocity squared” and $\ 0.5 * m * v ** 2$ all start to converge to the same region of a high-dimensional geometric space, despite sharing essentially zero surface-level features.
This suggests the interlingua isn’t just for human languages — it might be for anything that expresses structured meaning. These results are not as strong as for languages, but these are also models much less ‘intelligent’ than the best from Anthropic and OpenAI. I would speculate that the better a model is at reasoning, the more we see this effect (anyone working at either Lab is more than welcome to reach out and offer me access to test this theory!).
The Implication
If you take this result at face value (five models, two experiments, the same convergent structure every time) then the most conservative reading is: transformer-based language models discover that the most efficient internal organisation separates meaning from format. Content goes to one space, language/syntax/notation goes to the I/O layers. This is an engineering observation about how these models solve their training objective.
The more aggressive reading is that this separation reflects something about the structure of meaning itself. That there exists a space of semantic relationships, that photosynthesis is closer to respiration than to contract law, regardless of whether you express it in Mandarin or in LaTeX, and that gradient descent on enough data will reliably find it. Not totally unexpected given precedents like word2vec, but it’s fascinating that it’s structurally separate, and that duplicating parts of this structure materially improves multiple benchmarks.
At least in these systems, Sapir and Whorf seem to have it backwards. Language doesn’t shape thought. The model appears to compress away much of the language-specific structure before reintroducing it during decoding. And Chomsky was half right: there is a universal structure underneath. But it’s not grammar; it’s learned vector geometry — a continuous space of distances and directions between concepts, not a rulebook of syntactic primitives.
What’s Next
Several experiments would strengthen or complicate this picture:
- Adversarial pairs. “The bank of the river” vs “the bank raised rates” — testing whether the semantic space resolves polysemy correctly.
- Cross-lingual steering. Taking a direction vector between topics in one language and applying it to another language’s representations. If the space is truly shared, cross-lingual vector arithmetic should work.
- Scaling laws. Does the universal space emerge more cleanly in larger models? Do smaller models show a noisier or more entangled version of the same structure?
- Scaling the evaluation. 64 natural-language sentences and 36 code/math samples are proofs of concept. Running this on established multilingual benchmarks like FLORES-200 or XNLI — with hundreds of languages and thousands of sentence pairs — would map the exact topology of the space. Adding more formal languages (Rust, Haskell, maybe assembly) would test where different modal convergence breaks down.
- Culturally entangled concepts. Testing with concepts that resist clean translation — Schadenfreude, Japanese wabi-sabi, Quechua evidentiality markers — to probe the limits of universality.
The pattern in the data is clear, the interpretation is provocative: The GPUs will continue to grind.
Code and datasets: github.com/dnhkng/RYS
Citing this work
1
2
3
4
5
6
7
@article{ng2026sapirwhorf,
title = {LLM Neuroanatomy III: Do LLMs Break the Sapir-Whorf Hypothesis?},
author = {Ng, David Noel},
year = {2026},
month = {March},
url = {https://dnhkng.github.io/posts/sapir-whorf/}
}
Enjoyed this deep-dive?
Get my next piece on AI hardware, biophysics, or random optimisation hacks delivered straight to your inbox.